2019/05/29 nginx企业应用配置02
本文共 1782 字,大约阅读时间需要 5 分钟。



 就是把这个url起个别名,让这个url指向另外的 当访问bbs,其实是访问web/forum下的文件
就是把这个url起个别名,让这个url指向另外的 当访问bbs,其实是访问web/forum下的文件 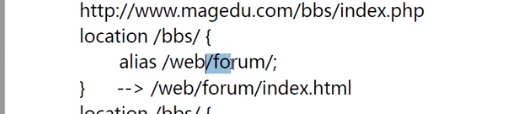 如果是root,就会有所区别
如果是root,就会有所区别  修改配置文件
修改配置文件 
 创建文件启动服务
创建文件启动服务 
 改成root对比一下
改成root对比一下 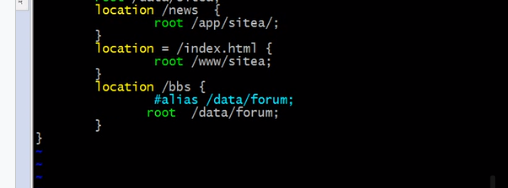
 就是bbs下的文件
就是bbs下的文件 
 不指定文件名,就默认index.html
不指定文件名,就默认index.html 
 错误页面,访问不存在的页面就会自动跳转
错误页面,访问不存在的页面就会自动跳转  这就是nginx是404错误
这就是nginx是404错误 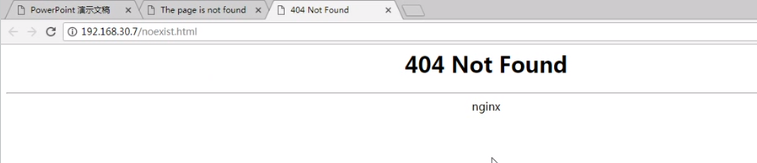 京东报错的页面就比较好看
京东报错的页面就比较好看  这个页面是360浏览器生成的页面,如果访问网站不存在的情况下,就会出现,劫持原本的页面
这个页面是360浏览器生成的页面,如果访问网站不存在的情况下,就会出现,劫持原本的页面  可以不用系统 的404错误页面
可以不用系统 的404错误页面 
 建立一个404页面
建立一个404页面 
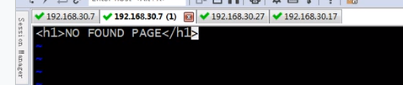
 查看是否起作用
查看是否起作用 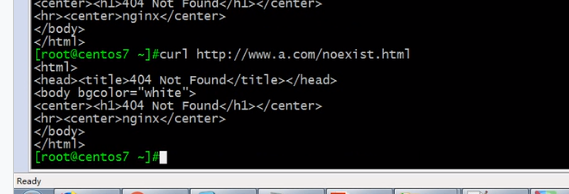 错误页面放错位置了
错误页面放错位置了 
 这个就是我们自己定义的
这个就是我们自己定义的  但是这样定义,像360这样的浏览器就会劫持你 把a。conf设置成默认,因为一直做实验
但是这样定义,像360这样的浏览器就会劫持你 把a。conf设置成默认,因为一直做实验 
 原来的c.com就不需要是默认的了
原来的c.com就不需要是默认的了 
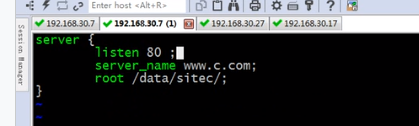
 现在通过ip地址访问就是a.com网站
现在通过ip地址访问就是a.com网站 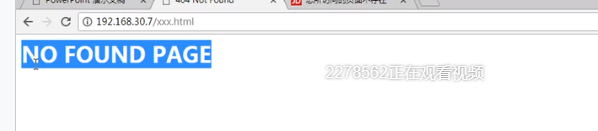
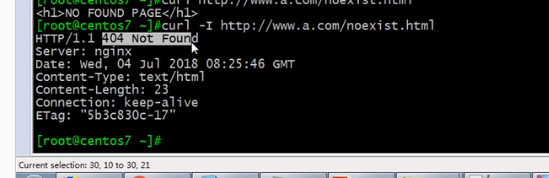 为了避免被劫持有一个好方法,报错的时候重定向到200响应码
为了避免被劫持有一个好方法,报错的时候重定向到200响应码 
 返回200的响应码,但是看到的页面还是404页面
返回200的响应码,但是看到的页面还是404页面  京东也怕被劫持
京东也怕被劫持 
 现在再去访问,就是200了
现在再去访问,就是200了  响应码变成200,页面还是404
响应码变成200,页面还是404  360做流氓软件出身,3721插件卖给雅虎了,一下发了,后来做了安全公司
360做流氓软件出身,3721插件卖给雅虎了,一下发了,后来做了安全公司 
 try_files url 当去访问具体路径的时候,如果找不到内容了,(找一个内容的时候,要按照什么顺序来寻找数据) 当访问images下的页面的时候先去找这个目录下对应的$uri (变量)
try_files url 当去访问具体路径的时候,如果找不到内容了,(找一个内容的时候,要按照什么顺序来寻找数据) 当访问images下的页面的时候先去找这个目录下对应的$uri (变量) 

 当去访问一个网站的时候,比如images/a.jpg 你要访问的uri是什么就进到具体目录里寻找数据 找的时候先去找images下面有没有a.jpg,如果有就把页面返回给用户,没有就找default.gif
当去访问一个网站的时候,比如images/a.jpg 你要访问的uri是什么就进到具体目录里寻找数据 找的时候先去找images下面有没有a.jpg,如果有就把页面返回给用户,没有就找default.gif  如果找不到这个uri,就去找这个uri下的index文件 如果再访问不了,就访问uri.html,返回一个404的错误
如果找不到这个uri,就去找这个uri下的index文件 如果再访问不了,就访问uri.html,返回一个404的错误  最后一个参数是必须存在的
最后一个参数是必须存在的 
 复制一个图片,正常访问在images下
复制一个图片,正常访问在images下 
 正常访问什么就返回什么
正常访问什么就返回什么  访问uri就返回什么uri,没有就用默认的jpg返回
访问uri就返回什么uri,没有就用默认的jpg返回 


 也可以直接返回一个404
也可以直接返回一个404 
 现在就对了
现在就对了 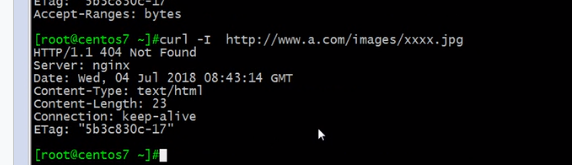
 默认系统应该已经支持长连接,keepalive_timeout telnet测试一下长连接 没有断开就说明是长连接,正常是已经断开了、
默认系统应该已经支持长连接,keepalive_timeout telnet测试一下长连接 没有断开就说明是长连接,正常是已经断开了、
 主页面在data下
主页面在data下  说明默认就是长连接,长连接默认是75秒断开,一般75秒偏长,但是结合业务
说明默认就是长连接,长连接默认是75秒断开,一般75秒偏长,但是结合业务 
 链接多少次的时候才断开,默认100
链接多少次的时候才断开,默认100  达到多少个请求断开
达到多少个请求断开  可以对浏览器类型禁止长连接
可以对浏览器类型禁止长连接  向客户端发送请求的超时时长
向客户端发送请求的超时时长

 一般用get命令,请求报文头部有三部分首部行,第二行是首部字段 ,第三个就是body
一般用get命令,请求报文头部有三部分首部行,第二行是首部字段 ,第三个就是body  **但是如果是get方法,body一般是没有数据的 put,post(提交)可能body里面有数据 ** 把body放到缓冲区中,默认为16k,当这个16k超过一定大小,就放到磁盘路径里面 (传附件本来就要上传到服务器的磁盘里,为何把缓存放到磁盘的一个路径下呢, 如果磁盘上存放的内容很多的话,就要从这个路径一点点地找, 数据存放在磁盘上,就需要通过文件系统一遍一遍地找,通过节点表,性能还是比较低下的,
**但是如果是get方法,body一般是没有数据的 put,post(提交)可能body里面有数据 ** 把body放到缓冲区中,默认为16k,当这个16k超过一定大小,就放到磁盘路径里面 (传附件本来就要上传到服务器的磁盘里,为何把缓存放到磁盘的一个路径下呢, 如果磁盘上存放的内容很多的话,就要从这个路径一点点地找, 数据存放在磁盘上,就需要通过文件系统一遍一遍地找,通过节点表,性能还是比较低下的, 
 、 如何来提高这个速度
、 如何来提高这个速度  **把数据做哈希运算,哈希运算得到的内容就是一个哈希值,比如sha1sum 1,2,2 比如就是最后取1个值 最后2,3位取 2 最后4,5位就取2 **
**把数据做哈希运算,哈希运算得到的内容就是一个哈希值,比如sha1sum 1,2,2 比如就是最后取1个值 最后2,3位取 2 最后4,5位就取2 **  12,就会建立文件夹叫89
12,就会建立文件夹叫89 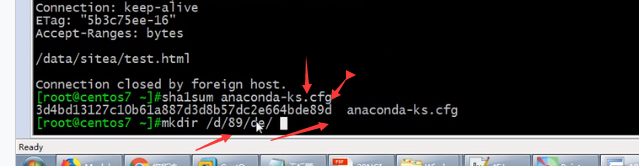 利用哈希值来组成数据,将来时以d结尾的都放在d目录下 16进制就是0-f,16*16=256字符 相当于分到了这么多的目录组合里去
利用哈希值来组成数据,将来时以d结尾的都放在d目录下 16进制就是0-f,16*16=256字符 相当于分到了这么多的目录组合里去 
 光文件夹就100万多
光文件夹就100万多  一亿个文件放在100万文件加里,每个文件夹才放100个 如果一个目录放1亿那就需要等很久
一亿个文件放在100万文件加里,每个文件夹才放100个 如果一个目录放1亿那就需要等很久  git什么的也是这种思想,因为用这种方式存放数据,系统搜索磁盘数据,相对效率较高
git什么的也是这种思想,因为用这种方式存放数据,系统搜索磁盘数据,相对效率较高  达到多大放磁盘里
达到多大放磁盘里  1用一个字符就用0-f 2就用两个字符代替 最多可以达到100万的文件夹 一级文件夹有16个 二级每个文件夹都有=16256个 三级每个文件夹16256*256
1用一个字符就用0-f 2就用两个字符代替 最多可以达到100万的文件夹 一级文件夹有16个 二级每个文件夹都有=16256个 三级每个文件夹16256*256  只要跳30个文件,可以把一亿个文件轻松找到,效率高 缓存数据也是一样的
只要跳30个文件,可以把一亿个文件轻松找到,效率高 缓存数据也是一样的 
转载地址:http://xfkgn.baihongyu.com/
你可能感兴趣的文章
整合.NET WebAPI和 Vuejs——在.NET单体应用中使用 Vuejs 和 ElementUI
查看>>
“既然计划没有变化快,那制订计划还有个卵用啊!”
查看>>
C#实现网页加载后将页面截取成长图片
查看>>
C# 在自定义的控制台输出重定向类中整合调用方信息
查看>>
【gRPC】ProtoBuf 语言快速学习指南
查看>>
C# 9 新特性 —— 补充篇
查看>>
Asp.Net Core使用Skywalking实现分布式链路追踪
查看>>
浅谈CLR基础知识
查看>>
Xamarin使XRPC实现接口/委托远程调用
查看>>
如何成功搞垮一个团队?
查看>>
.NET开源5年了,这些宝藏你还没get?
查看>>
【日常排雷】 .Net core 生产环境appsetting读取失败
查看>>
从内存中释放Selenium chromedriver.exe
查看>>
如何在 C# 中使用 MSMQ
查看>>
小试elsa
查看>>
巧用 Lazy 解决.NET Core中的循环依赖关系
查看>>
微前端架构在容器平台的应用
查看>>
C# 中的 null 包容运算符 “!” —— 概念、由来、用法和注意事项
查看>>
仓储模式到底是不是反模式?
查看>>
【One by One系列】IdentityServer4(一)OAuth2.0与OpenID Connect 1.0
查看>>